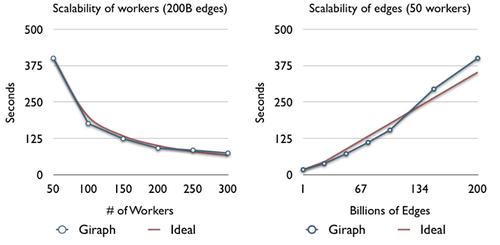
Facebook has found that Giraph scales near linearly with the number of workers or the problem size.
Move over Hadoop, there is another highly scalable data processing powerhouse in town: Apache Giraph. Facebook is using the technology to bring a new style of search to its billion users.
When Facebook built its Graph Search service, the social networking company picked Giraph over other social graphing technologies -- such as the Hadoop-based Apache Hive and GraphLab -- because of Giraph's speed and immense scalability.
"Analyzing these real-world graphs at our scale ... with available software was impossible last year. We needed a programming framework to express a wide range of graph algorithms in a simple way and scale them to massive datasets," wrote Facebook software engineer Avery Ching, in a blog post that discussed Facebook's use of the technology.
With a little modification, Facebook has used Giraph to analyze a trillion edges, or connections between different entities, in under four minutes.
In addition to using Giraph for its Graph Search, Facebook also plans to use the software for other duties such as targeting ads and ranking data.
Launched in January, Facebook's Graph Search service provides a way for users to query Facebook's massive collection of user-generated data and get back personalized results.
"Open Graph allows application developers to connect objects in their applications with real-world actions (such as user X is listening to song Y)," Ching explained.
A social graph maps the complex relationships between many different entities (called nodes). A node can be anything: a person, a restaurant, a city. They are connected by edges. An edge, for instance, asserts that a particular person may live in a certain city.
Using the Bulk Synchronous Parallel model of computing, Google designed Pregel to generate graphs from very large data sets, using lots of commodity servers.
Like it did with Hadoop, Yahoo bequeathed Giraph to the Apache Software Foundation, where it is now a fully open-source project worked on by developers from Facebook, LinkedIn, Twitter and Hortonworks.
Because Giraph is written in Java, Ching explained, it can connect very easily with the various parts of Facebook's Hadoop deployment, which it relies upon for data storage management and resource scheduling.
Facebook stores its user-generated data in a data warehouse running on Apache Hive, a component of Hadoop. Giraph, however, can generate graphs four times faster than Hive itself. Because it runs on Hadoop's MapReduce, a Giraph job can be split across multiple servers so it can be executed in parallel.
Facebook modified Giraph in a number of ways to make it run more efficiently, according to Ching.
Company engineers devised a number of tweaks to trim Giraph's memory usage on servers. "Giraph was a memory behemoth due to all data types being stored as separate Java objects," Ching wrote.
To improve Giraph's scalability, Facebook linked it with the Netty event-driven framework.
In one test using user interaction data, Facebook was able to use Giraph to create a 1 trillion-edge social graph in under four minutes, using 200 commodity servers.
Joab Jackson covers enterprise software and general technology breaking news for The IDG News Service. Follow Joab on Twitter at @Joab_Jackson. Joab's e-mail address is Joab_Jackson@idg.com
In the third and final episode of our 3-part CMO50 video series exploring modern marketing and why it’s become a matter of trust, we’re delighted to be joined by Telstra’s former CMO and now digital services and sales executive, Jeremy Nicholas, and Adobe VP Marketing Asia-Pacific and Japan, Duncan Egan.
Flash back to the classic film, Willy Wonka and the Chocolate Factory. Television-obsessed Mike insists on becoming the first person to be ‘sent by Wonkavision’, dematerialising on one end, pixel by pixel, and materialising in another space. His cinematic dreams are realised thanks to rash decisions as he is shrunken down to fit the digital universe, followed by a trip to the taffy puller to return to normal size.
Why is it there is no shortage of leadership development materials, yet outstanding leadership is so rare? Despite having access to so many leadership principles, tools, systems and processes, why is it so hard to develop and improve as a leader?
As a nation united by sport, brands are beginning to learn money alone won’t talk without aligned values and action. If recent events with major leagues and their players have shown us anything, it’s the next generation of athletes are standing by what they believe in – and they won’t let their values be superseded by money.